Documentation Index
Fetch the complete documentation index at: https://generaltranslation.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
v2 の Search Posts エンドポイントを使用すると、作成した検索クエリに基づいて、関心のあるトピックに関連する投稿を取得できます。v2 の Search Posts には 2 種類のエンドポイントがあります。承認済みアカウントを持つすべての開発者が利用でき、最大 7 日前までの投稿を検索できる recent search と、Academic Research product track に承認された研究者のみが利用でき、2006 年 3 月までさかのぼってアーカイブ全体の投稿を検索できる full-archive search です。
検索機能全体の内容は、
search overview ページ
で確認できます。
これらの Search Posts エンドポイントは、縦断的研究や過去のトピック・イベントの分析など、学術研究者にとってよくあるユースケースの一つに対応するものです。
このチュートリアルでは、公開されている X データの完全な履歴を検索するために full-archive search エンドポイントを利用したい研究者向けに、ステップバイステップのガイドを提供します。また、ジオタグ付きの投稿を取得するなど、データセットを構築するさまざまな方法と、クエリに対して利用可能な投稿をページングしながら取得する方法も示します。
現在、このエンドポイントは
Academic Research プロダクトトラック
の一部としてのみ利用できます。
このエンドポイントを利用するには、
アクセス申請
を行う必要があります。
このトラックの
申請手順と要件の詳細
をご覧ください。
Academic Research プロダクトトラックの利用が承認されると、
Developer Console 上に
Academic Project が表示されます。
「Apps」セクションから「Add App」をクリックして、
X App を Project に接続します。
 次に、既存の App を選択してプロジェクトに接続できます (下図のとおり) 。
次に、既存の App を選択してプロジェクトに接続できます (下図のとおり) 。
 または、新しい App を作成して名前を付け、「Complete」をクリックすることで、
新しい App を Academic Project に接続することもできます。
または、新しい App を作成して名前を付け、「Complete」をクリックすることで、
新しい App を Academic Project に接続することもできます。
 これにより API キーと
Bearer Token
が発行され、これらを使用してフルアーカイブ検索エンドポイントに接続できるようになります。
これにより API キーと
Bearer Token
が発行され、これらを使用してフルアーカイブ検索エンドポイントに接続できるようになります。
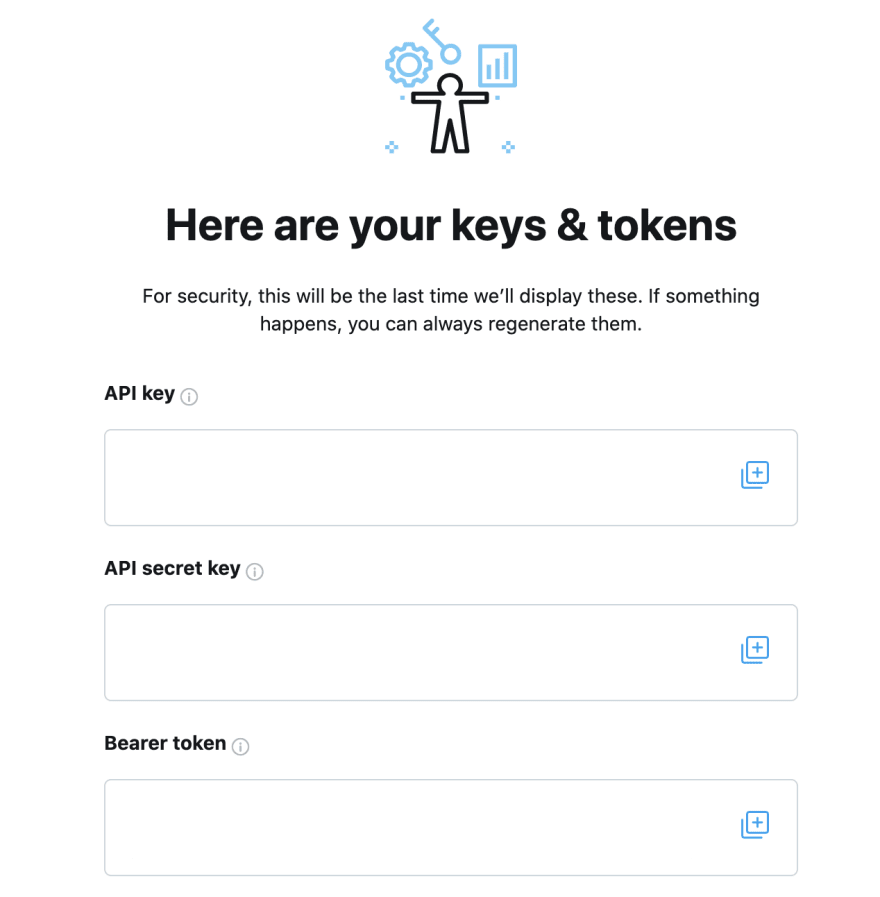 注意
上記のスクリーンショットではキーは非表示になっていますが、
ご自身の Developer Console では API Key、API Secret Key、
および Bearer Token の実際の値を確認できます。
これらのキーと Bearer Token は、フルアーカイブ検索エンドポイントを呼び出す際に必要になるため、
必ず保存しておいてください。
以下の cURL コマンドは、@XDevelopers のアカウントから過去の投稿を取得する方法を示しています。$BEARER_TOKEN を自分のベアラートークンに置き換え、リクエスト全体をターミナルに貼り付けてから “return” キーを押してください。
注意
上記のスクリーンショットではキーは非表示になっていますが、
ご自身の Developer Console では API Key、API Secret Key、
および Bearer Token の実際の値を確認できます。
これらのキーと Bearer Token は、フルアーカイブ検索エンドポイントを呼び出す際に必要になるため、
必ず保存しておいてください。
以下の cURL コマンドは、@XDevelopers のアカウントから過去の投稿を取得する方法を示しています。$BEARER_TOKEN を自分のベアラートークンに置き換え、リクエスト全体をターミナルに貼り付けてから “return” キーを押してください。
curl --request GET 'https://api.x.com/2/tweets/search/all?query=from:xdevelopers' --header 'Authorization: Bearer $BEARER_TOKEN'
max_results パラメータを使用し、以下のように 1 リクエストあたり最大 500 件の投稿まで指定できます。
curl --request GET 'https://api.x.com/2/tweets/search/all?query=from:xdevelopers&max_results=500' --header 'Authorization: Bearer $BEARER_TOKEN'
query パラメータを使用すると、
検索したいデータを指定できます。たとえば、covid という単語、または
coronavirus という単語を含むすべての投稿を取得したい場合は、
括弧の中で OR 演算子を使用し、クエリを
(covid OR coronavirus) のように指定できます。この場合、API 呼び出しは
次のようになります。
curl --request GET 'https://api.x.com/2/tweets/search/all?query=(covid%20OR%20coronavirus)&max_results=500' --header 'Authorization: Bearer $BEARER_TOKEN'
curl --request GET 'https://api.x.com/2/tweets/search/all?query=covid19%20-is:retweet&max_results=500' --header 'Authorization: Bearer $BEARER_TOKEN'
start_time パラメーターと end_time パラメーターを使って過去の投稿を取得する
curl --request GET 'https://api.x.com/2/tweets/search/all?query=from:XDevelopers&start_time=2020-12-01T00:00:00.00Z&end_time=2021-01-01T00:00:00.00Z' --header 'Authorization: Bearer $BEARER_TOKEN'
curl --request GET
'https://api.x.com/2/tweets/search/all?query=from:xdevelopers%20has:geo' --header
'Authorization: Bearer $BEARER_TOKEN'
place_country 演算子を使用することで、ジオデータを持つ投稿を特定の国に限定できます。以下の cURL コマンドは、米国に紐づく @XDevelopers ハンドルからのすべての投稿を取得します。
curl --request GET
'https://api.x.com/2/tweets/search/all?query=from:xdevelopers%20place_country:US'
--hbasheader 'Authorization: Bearer XXXXX'
next_token を使って 500 件を超える過去の投稿を取得する
next_token が含まれます。この next_token を API 呼び出しに指定することで、そのクエリに対して次に取得可能な投稿を取得できます。この next_token は JSON レスポンス内の meta オブジェクトに含まれており、次のような形式になります。
{ "newest_id": "12345678...", "oldest_id": "12345678...", "result_count": 500,
"nebashxt_token": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" }
curl --request GET
'https://api.x.com/2/tweets/search/all?max_results=500&query=covid&next_token=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
--header 'Authorization: Bearer $BEARER_TOKEN'
next_token が利用可能かどうかを確認しつつ、収集したい投稿数にまだ達していない場合は、新しい next_token を各リクエストで指定して full-archive エンドポイントを呼び出し続けることができます。
以下は、full-archive search エンドポイントを利用する際に役立つリソースです。ぜひフィードバックをお寄せください。このエンドポイントに関するご質問は @XDevelopers や community forums までお寄せください。