Documentation Index
Fetch the complete documentation index at: https://generaltranslation.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
v2에서 제공하는 Search Posts 엔드포인트를 사용하면
여러분이 작성한 검색 쿼리를 기반으로 관심 있는 주제와 관련된 포스트를
받을 수 있습니다. v2 Search Posts에는 서로 다른 두 개의 엔드포인트가 있습니다.
모든 승인된 개발자 계정이 사용할 수 있고 최대 7일 이내의 포스트를
검색할 수 있는 최근 검색(recent search)과,
Academic Research product track에
승인된 연구자만 사용할 수 있으며,
2006년 3월까지 거슬러 올라가는 전체 포스트 아카이브를 검색할 수 있는
전체 아카이브 검색(full-archive search)이 있습니다.
검색 기능 전체는
검색 개요 페이지에서 확인할 수 있습니다.
이러한 Search Posts 엔드포인트는 종단 연구나 과거 주제 및 이벤트 분석 등
학술 연구자들이 가장 많이 활용하는 사용 사례 중 하나를 다룹니다.
이 튜토리얼은 전체 아카이브 검색 엔드포인트를 사용해 공개 X
데이터의 전체 이력을 검색하려는 연구자를 위한 단계별 가이드를 제공합니다.
또한 위치 정보가 포함된 포스트를 가져오는 등 다양한 방식으로 데이터셋을
구성하는 방법과, 특정 쿼리에 대해 사용 가능한 포스트를 페이지 단위로
순회하는 방법도 설명합니다.
현재 이 endpoint는
Academic Research 제품 트랙의 일부로만 사용할 수 있습니다.
이 endpoint를 사용하려면
액세스 권한을 신청해야 합니다.
이 트랙에 대한
신청 절차 및 요구 사항을 자세히 알아보세요.
Academic Research 제품 트랙 사용 승인을 받으면
개발자 콘솔에서 Academic
Project를 볼 수 있습니다. “Apps”
섹션에서 “Add App”을 클릭해
X App을(를) Project에 연결합니다.
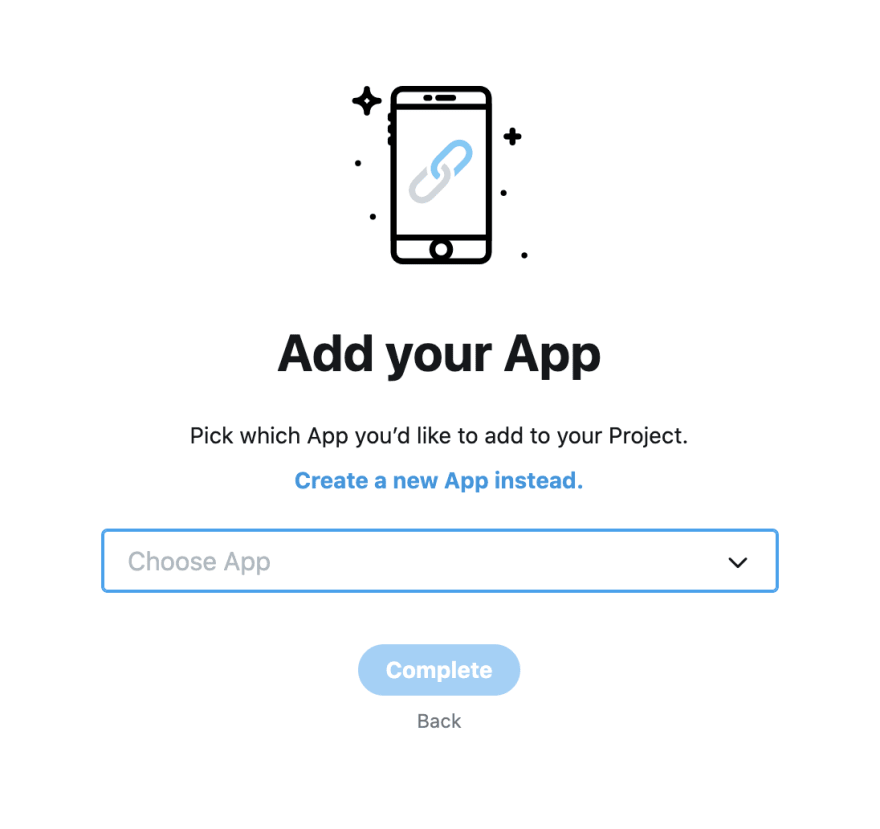
 그다음, 기존 App 중 하나를 선택해 아래와 같이 프로젝트에 연결할 수
있습니다.
그다음, 기존 App 중 하나를 선택해 아래와 같이 프로젝트에 연결할 수
있습니다.
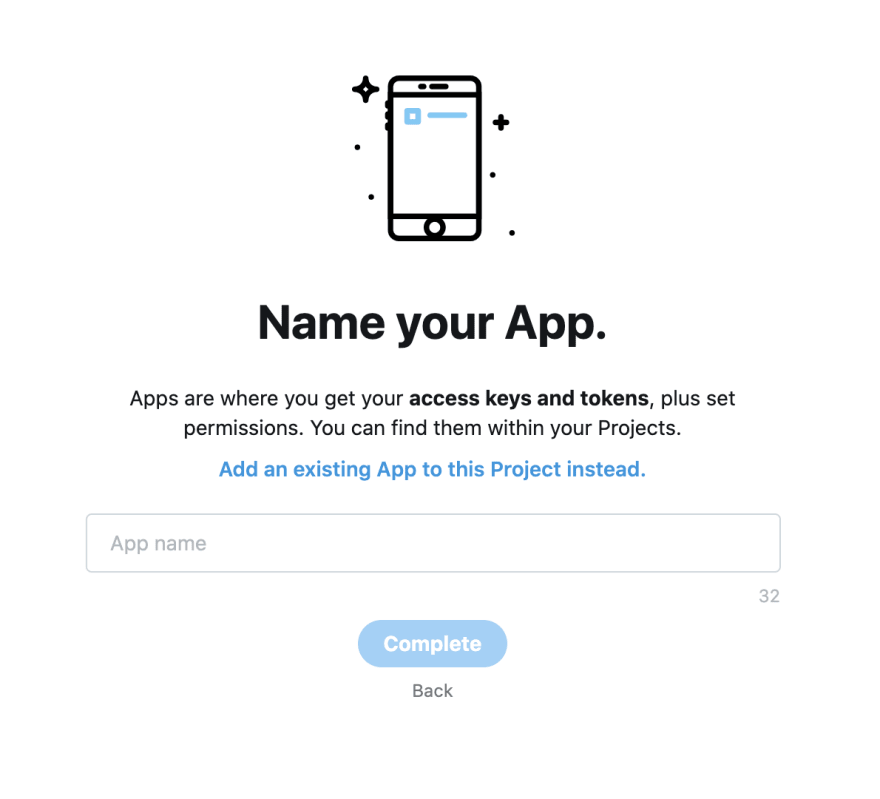
 또는 새 App을 생성하고 이름을 지정한 뒤 완료를 클릭하여 Academic
Project에 새 App을 연결할 수도 있습니다.
또는 새 App을 생성하고 이름을 지정한 뒤 완료를 클릭하여 Academic
Project에 새 App을 연결할 수도 있습니다.
 이렇게 하면 API 키와, 이후 전체 아카이브 검색 엔드포인트에 연결하는 데 사용할
Bearer Token을(를) 받게 됩니다.
이렇게 하면 API 키와, 이후 전체 아카이브 검색 엔드포인트에 연결하는 데 사용할
Bearer Token을(를) 받게 됩니다.
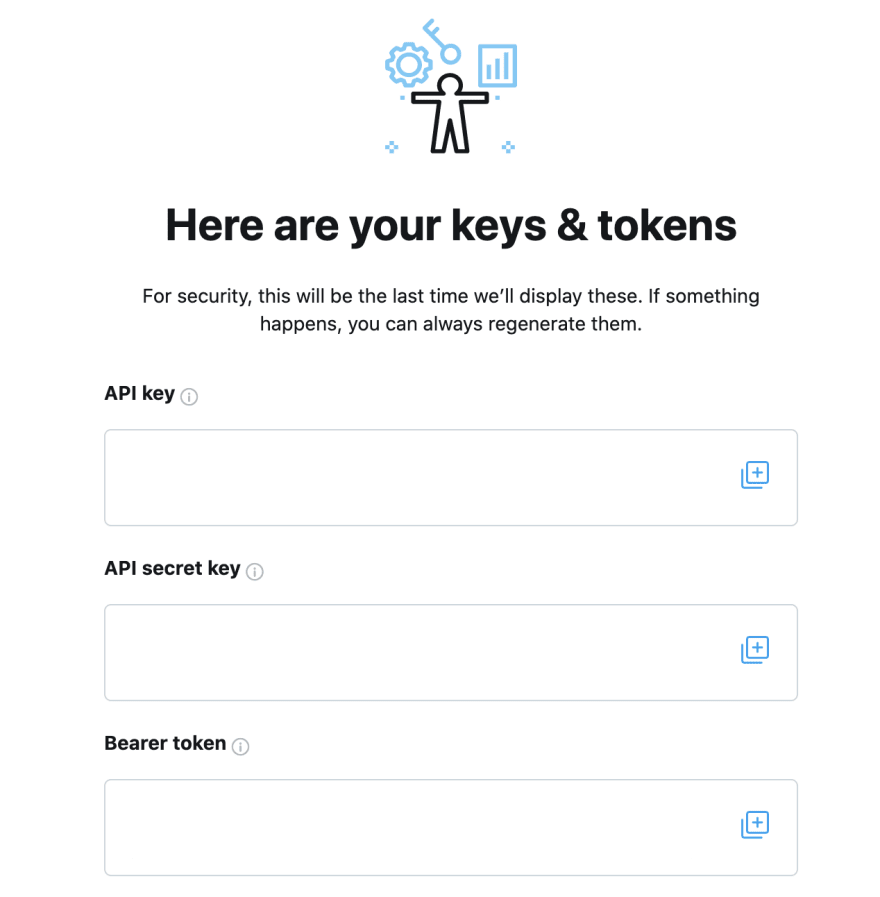 주의 사항
위 스크린샷의 키 값은 숨김 처리되어 있지만, 실제 개발자 콘솔에서는
API Key, API Secret Key, Bearer Token의 실제 값을 확인할 수 있습니다.
이 키들과 Bearer Token은 전체 아카이브 검색 엔드포인트를 호출하는 데
필요하므로 반드시 저장해 두십시오.
아래 cURL 명령은 @XDevelopers 계정에서 과거 포스트를 가져오는 방법을
보여줍니다. $BEARER_TOKEN을 자신의 Bearer Token으로 바꾸고, 전체 요청을
터미널에 붙여넣은 뒤 “Enter” 키를 누르세요.
주의 사항
위 스크린샷의 키 값은 숨김 처리되어 있지만, 실제 개발자 콘솔에서는
API Key, API Secret Key, Bearer Token의 실제 값을 확인할 수 있습니다.
이 키들과 Bearer Token은 전체 아카이브 검색 엔드포인트를 호출하는 데
필요하므로 반드시 저장해 두십시오.
아래 cURL 명령은 @XDevelopers 계정에서 과거 포스트를 가져오는 방법을
보여줍니다. $BEARER_TOKEN을 자신의 Bearer Token으로 바꾸고, 전체 요청을
터미널에 붙여넣은 뒤 “Enter” 키를 누르세요.
curl --request GET 'https://api.x.com/2/tweets/search/all?query=from:xdevelopers' --header 'Authorization: Bearer $BEARER_TOKEN'
curl --request GET 'https://api.x.com/2/tweets/search/all?query=from:xdevelopers&max_results=500' --header 'Authorization: Bearer $BEARER_TOKEN'
query 매개변수를 사용하면
검색하려는 데이터를 지정할 수 있습니다. 예를 들어
covid 또는 coronavirus라는 단어를 포함하는 모든 포스트를
가져오려면, 괄호 안에서 OR 연산자를 사용해
쿼리를 (covid OR coronavirus)와 같이 작성할 수 있고,
이에 따라 API 호출은 다음과 같은 형태가 됩니다:
curl --request GET 'https://api.x.com/2/tweets/search/all?query=(covid%20OR%20coronavirus)&max_results=500' --header 'Authorization: Bearer $BEARER_TOKEN'
curl --request GET 'https://api.x.com/2/tweets/search/all?query=covid19%20-is:retweet&max_results=500' --header 'Authorization: Bearer $BEARER_TOKEN'
start_time 및 end_time 파라미터를 사용하여 과거 포스트 가져오기
curl --request GET 'https://api.x.com/2/tweets/search/all?query=from:XDevelopers&start_time=2020-12-01T00:00:00.00Z&end_time=2021-01-01T00:00:00.00Z' --header 'Authorization: Bearer $BEARER_TOKEN'
curl --request GET
'https://api.x.com/2/tweets/search/all?query=from:xdevelopers%20has:geo' --header
'Authorization: Bearer $BEARER_TOKEN'
place_country 연산자를 사용하여 지리 정보가 포함된 포스트를 특정 국가로 제한할 수 있습니다. 아래 cURL 명령어는 미국에서 작성된 @XDevelopers 계정의 모든 포스트를 가져옵니다:
curl --request GET
'https://api.x.com/2/tweets/search/all?query=from:xdevelopers%20place_country:US'
--hbasheader 'Authorization: Bearer XXXXX'
next_token을 사용하여 500개가 넘는 과거 포스트 가져오기
{ "newest_id": "12345678...", "oldest_id": "12345678...", "result_count": 500,
"nebashxt_token": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" }
curl --request GET
'https://api.x.com/2/tweets/search/all?max_results=500&query=covid&next_token=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
--header 'Authorization: Bearer $BEARER_TOKEN'